
Chapter 4: Phonology
Speech sounds
Chapter Preview
4.1 Introduction
Any sound, whether used in speech or otherwise, can be characterised in terms of its quality. Sound quality refers to a specific set of acoustic properties that distinguishes one sound from another.
Being about language, this book is concerned with speech sounds, sounds produced by human beings for the purposes of linguistic communication. This definition encompasses the two branches into which the study of speech sounds divides:
- Phonetics deals with the articulatory capabilities of the vocal tract, and therefore with an ability shared by all human beings. These capabilities are the object of articulatory phonetics, the branch of phonetics that we deal with in this chapter. Articulatory phonetics studies how speech sounds are produced (articulated) in the human vocal tract. Auditory phonetics and acoustic phonetics constitute further sub-branches of phonetics, not dealt with this in this book. Auditory phonetics studies the mechanisms involved in speech audition, i.e. how listeners perceive speech sounds, while acoustic phonetics studies the physical characteristics of speech sounds.
- Phonology deals with sounds that serve linguistic purposes. These are sounds whose patterning conveys meaning. These sounds are recognised by speakers and listeners as linguistic signals in the language(s) that are available to them, and are therefore shared by speakers who share a language. We will look more closely at phonology in the next chapter.
In talking about sounds, we need to keep in mind that there is often no one- to-one correspondence between speech sounds and their spellings. So, we need to (re)train ourselves to listen to speech instead of reading printed forms of it. Here are a few examples of sound-spelling discrepancies in English. The words threw and through are pronounced in exactly the same way, as are knows and nose: when spoken out of context, we can’t tell which is “witch”. Conversely, the English letter sequence –ough has several different pronunciations, as in words like cough, dough or through, and the sound [k] can be spelt in at least eight different ways, as shown by the bolded letters of the following words:
(5.1) tack , cat, mechanic, squid, beak , acquire, accordion, grotesque
A few more examples from English appear in the Food for thought section at the end of this chapter.
Activity 4.1
4.2 The production of speech sounds
In order to communicate through speech, human beings move the lower part of their faces, in a frenzy of rapidly shifting and very precise configurations. If you think of yourself as a lazy or slurred speaker, and would dismiss the word precise as inapplicable to you, just take some time to observe the tremendous effort that small children put into the task of training the muscles that command the production of speech: you also had to go through this painstaking workout of speech musculature, in order to be able to “slur” fluently.
The lower jaw, being mobile, stands for the visible part of speech configurations. The role of the lips in speech is clearly visible too, as is, at times, the configuration of the tip of the tongue and the teeth in the articulation of certain speech sounds. However, most speech configurations take place inside the oral cavity, anywhere along the vocal tract. They are therefore difficult to see, but fairly easy to feel. The bulk of this chapter is dedicated to showing you what it takes, and how it feels, to pronounce a range of common speech sounds.
4.2.1 The vocal tract
The vocal tract forms an inverted L-shaped tube that stretches from the larynx upwards to the lips. The angle of the L is at the back of your throat. The larynx, or the voice box, is located mid-way down the front of your neck. If you’re male, you may find that the so-called “Adam’s apple” of your larynx can be quite protruding. The vocal tract includes the nasal cavities, which are located inside and behind your nose, as optional resonator.
We normally speak while breathing out (you can try uttering a few words, or maintaining a conversation while breathing in, to get a feeling of how unnatural this is). This explains why speaking for long periods of time can be quite tiring. The repeated interruptions of the airflow that make speech possible disrupt the normal rhythm of breathing. Speech sounds are produced by means of modifications imposed on exhaled air, as it flows through the vocal tract. These modifications are brought about by movement of the articulators, each of the component organs and locations in the vocal tract that play a role in the production of speech sounds. Generally, the active articulators along the lower jaw move towards the passive articulators in the upper jaw. Both lips, lower and upper, can be active articulators.
Instead of providing you with the usual labelled diagram of the vocal tract found in most introductory material on phonetics, we offer in this chapter “hands-on” acquaintance with the basic anatomy and physiology of your oral cavity. We will show you around your own vocal tract, making it clear to you what goes on inside it when you speak. In the process, the reason why so many apparently obscure labels are needed for the description of speech sounds will, we hope, become clear to you. As a preliminary observation, keep in mind that just as we need different labels for words that behave differently, so we also need different labels for each of the vocal movements that produce a different speech sound.
In what follows, we provide you with a guided tour of your vocal tract, together with core speech configurations used in many languages, including English. In order to fully understand this chapter, you will need a mirror, a pencil or pen, and some privacy. Warn anyone near you not to panic at the noises you’ll be producing: phonetics must be practised, it cannot be learned otherwise. Better still, work through this chapter with a friend or two, willing to observe and be observed, and practise together! Just follow the Try the following trail.
4.2.2 Core speech configurations
Modifications along the length of the vocal tract affect its shape, and therefore its volume and resonance. Each modification thus produces a different sound. In this book, we deal with only a few of these modifications, most of which apply to most languages, including English. According to these modifications, speech sounds may be classified as voiced or voiceless, oral or nasal, and as vowels or consonants. We deal with each of these alternative articulations in turn.
Voiced vs. voiceless sounds
Try the following
Gently touch the section of your larynx that slightly protrudes at the front of your neck. Now say something like Good morning!, loud and clear. Can you feel the vibration under your fingers? This is the effect of your vocal cords at work, two folds of mucous tissue inside your larynx, that vibrate in order to produce voice. Now, still keeping your fingers in place, whisper Good morning! You’ll notice that the vibration is gone, because whisper has no voice. Your vocal cords do not vibrate when you whisper. When we produce speech sounds, the vocal cords can be in one of these two states:
- Closed, i.e. loosely brought together so that they vibrate when air flows through them. It is this vibration that creates what we call voice, resulting in voiced sounds.
- Open, i.e. pulled apart during the production of certain sounds, as they are during normal breathing or in whisper, resulting in voiceless sounds.
Try the following
With your fingers again in place on your larynx, say a long zzzz as in the beginning of the word zap and a long vvvv as in the beginning of the word vat, loud and clear. Next, say a long ssss (sap) and ffff (fat) sound. Did you notice that the first two sounds are voiced and the last two are voiceless? For a more dramatic contrast, say the same sounds with your hands over your ears, blocking them off. The two voiced sounds zzzz and vvvv produce a buzzing vibration, caused by voicing, inside your head, whereas the two voiceless sounds ssss and ffff produce a turbulent hiss of air.
Oral vs. nasal sounds
Try the following
With the tip of your tongue, touch the roof of your mouth. You’ll feel a bony surface, called the hard palate. Now drag the tip of your tongue back along the hard palate, as far back as it will go. You will notice that at the very back there is no bone: this is the soft palate, or velum.
Now close your lips tightly, and hum. Notice that you don’t need to use your jaw at all to make your voice heard. Sounds that are produced as you hum involve using your nasal cavity: you produce them as air flows out through your nose.
When we produce speech sounds, the soft palate can be in one of these two states:
- Raised against the top part of your pharynx, which is the back wall of your throat. When raised, the soft palate blocks the airflow to the nasal cavities, resulting in oral sounds.
- Lowered, causing the air to flow through the nasal cavities, as when you hum, resulting in nasal sounds.
Try the following
Say a long ah sound, as if calling for help by using the word Guard! Now, say the sound given in English spelling by –ng, as in the word bang. Repeat the sequence ah-ng-ah-ng-ah-ng-ah several times with no pauses in between, paying attention to what’s going on at the back of your mouth. You will feel the soft palate moving up and down, up for ah, which is an oral sound, and down for the nasal sound –ng. While doing this, pinch your nostrils together. You’ll have no problem producing the oral sound ah. But you’re no longer able to produce the nasal sound –ng, right? This is because when you pinch your nostrils together, air cannot flow out through your nose. To double-check that it is your soft palate moving, try saying ah-gah-gah-gah, where both sounds are oral. Pinch your nostrils together again, to confirm the difference between oral sounds like gah and nasal ones like ng. Assuming that you’ve had a bad cold at least once in your life, you’ll remember the strange resonance of your speech at the peak of it, when you have a blocked nose. Your listeners notice it, too. What happens is that air cannot flow out through your nasal cavities to produce the nasal sounds of speech. You may now realise that the popular expression “speaking through your nose” couldn’t be further from the facts: with a bad cold, you speak exclusively through your mouth.
Activity 4.2
Vowels vs. consonants
Try the following
Generally, we can say that:
- Consonants like t are produced by means of an obstruction to the airflow in the oral cavity. The lips, teeth and tongue form major consonantal obstructions.
- Vowels like ah are produced with no obstruction in the mouth: the shape of the vocal tract is modulated by different configurations of the tongue and lips.
Note that vowels and consonants refer to sounds, not letters/spellings. If you think there are five vowels in English, a, e, i, o, u, you will have reason to change your mind after you read the next chapter.
Activity 4.3
4.2.3 Consonants
We can produce different types of consonants, depending on two major factors. One is the degree of obstruction to the airflow, which gives us the manner of articulation of the consonant. The other is the location of the obstruction along the vocal tract, which tells us about the place of articulation of the consonant. These two factors operate independently of each other: in the same way that you can place obstacles of the same or different kinds just about anywhere along a cross-country obstacle course, you can have the same or different types of obstructions to the airflow in different places along your vocal tract.
Manner of articulation
- Plosives are pronounced with the velum raised, and involve contact of articulators. This means that the articulators first touch each other, and then separate.
- Non-plosive consonants, in contrast, involve close approximation of the articulators. This means that the articulators come very close to each other, without ever touching. One example is the class of fricative sounds, where the air is hissed (i.e. expelled with friction, hence their name) through a very narrow gap between the articulators.
Try the following
Check that the t-like sound that you produced before is a plosive: the tongue tip touches the alveolar ridge, thereby closing off oral airflow. The sudden release of this closure produces an explosive effect.
Try now the long sounds ssss and vvvv again. The friction that you hear means that there can be no contact between articulators: there must be a narrow channel somewhere that allows the air to hiss through it. Note that you can prolong fricative sounds for as long as you have air in your lungs. This is not possible with plosives, whose articulation is instantaneous. To check, try prolonging a t sound – chances are that you will go red in the face for lack of air, because of the plosive closure that is needed to produce this sound.
Place of articulation
- (Bi)labials involve one or both lips in their articulation.
- Alveolars involve the alveolar ridge as articulator.
- Velars involve the soft palate/velum as articulator.
Try the following
Now you know that t is not only plosive, it is also alveolar. You may also have guessed by now that the sounds spelt p and b are bilabials, involving both lips. Use your mirror (or your friends) to check these clearly visible articulations.
Say the sequence ah-ng-ah-ng-ah-ng-ah again, this time to check that the -ng sound involves contact between the back part of your tongue and the velum. So do the initial sounds in the words gap and cat. You can check this by saying ah-gah-gah-gah and ah-kah-kah-kah. All three sounds are therefore velar.
Now say vvvv and ffff, and concentrate on which articulators are involved in saying them. Use your mirror-friend to check. The upper lip plays no role in their articulation, but the lower lip does. These sounds are pronounced with the upper teeth very close to the lower lip. These sounds are therefore labial (and dental too: they involve the teeth, that your dentist checks out for you).
The place of articulation of sounds like ssss and zzzz is more difficult to check, because the whole of their articulation goes on inside the mouth. In terms of manner of articulation, both sounds are fricative. There is therefore no contact of articulators that may help us feel the place of articulation, in the absence of visual clues. But try this: say ssss and zzzz, then stop saying them but keep the articulators in exactly the same position, and breathe in quickly. You will feel a rush of cold air between the tip of your tongue and the alveolar ridge. This is the space inside your mouth that allows the articulation of the sounds ssss and zzzz, which shows that the constriction to the flow of air is located there. Both sounds are therefore alveolar.
4.2.4 Vowels
The articulation of different types of vowels depends on the movements of the tongue and lips. The body of the tongue can move vertically (up or down) and horizontally (front or back). The lips may be involved in the articulation of vowels, too.
The movements of the tongue body (the bulk of the tongue inside your mouth) are independent of one another. You can, for example, move your tongue up and down whilst bunching it up at the back of your mouth or, conversely, you can push it to the front or the back of your mouth while holding it high towards the hard palate. Try it.
Tongue-body movements are also independent of any movements of the tongue tip: the tongue tip is used in the production of consonants, not vowels. It may in fact come as surprise to you, especially if you are a body- builder, that the tongue is the best trained and most versatile muscle in your body. Its core role in speech is clear from the use of its name, “tongues”, to mean ‘languages’, in many languages around the world. We don’t notice the spectacular gymnastics show that goes on inside our mouths every time we speak because we have been practising this sophisticated skill since infancy. To get an idea of the range and power of tongue actions, remember it is used in chewing and swallowing, too. If you don’t believe us, try chewing on something while keeping your tongue motionless!
Vowel height
- High (or close) vowels are produced with the body of the tongue raised.
- Low (or open) vowels are produced with the body of the tongue lowered.
Try the following
Open your mouth wide and say a long aaaah again. While still saying ah, slowly raise your jaw. Use your mirror to check that you are indeed raising your jaw. You’ll find that, whatever you’re saying now, it’s not ah anymore. The vowel ah, in a word like cart, must be pronounced with a lowered jaw, and therefore a lowered tongue: it is an open vowel.
Now say a long iiiih vowel, as in the word see, and drop your jaw while saying it. You won’t be able to say ih anymore The vowel ih needs a raised tongue to be produced: it is a close vowel. The difference between open and close vowels explains why your doctor asks you to say aaaah, and not iiiih, in order to be able to examine your throat.
Vowel backness
- Front vowels are produced with the body of the tongue pushed forward in the oral cavity.
- Back vowels are produced with the body of the tongue pulled back/retracted.
Try the following
Say the vowel in the word cat, and then the vowel in the word cart, several times in a row. You’ll feel your tongue moving back and forth while doing this, back for the vowel in cart, and forwards for the vowel in cat. Use a mirror, to get visual feedback on this: it is easy to see because both these vowels are open.
Now try the same thing with the vowels in the words bean and boon. This is more difficult to feel because the boon vowel involves a distracting factor, which is the pouting, or rounding, of the lips. The difference in tongue movement is also impossible to see, because both vowels are close. So try this, instead. Take a pen, or a chopstick, and place it lengthways across your mouth, so that both ends of the pen/chopstick stick out from the sides of your mouth. Then bite it firmly as far back in your mouth as possible. Biting the pen/chopstick prevents the lips from moving in the articulation of the vowel in boon. Now say the vowels in bean and boon again. You’ll feel your tongue touching the pen in the articulation of the vowel in bean, but not of the vowel in boon. We thus conclude that the vowels in cat and bean are front vowels, whereas those in cart and boon are back vowels.
Lip rounding
- Rounded vowels are produced with rounded (pouting) lips.
- Unrounded vowels are produced with unrounded (spread) lips.
Try the following
Easiest comes last. Of the four vowels that we’ve discussed, the vowel in boon is the only one that involves the lips: the lips must be rounded in its articulation. This is also why your photographer asks you to say cheeeese and not choooose when prompting a smile from you: spread-lip vowels are “smiley” sounds.
4.3 The transcription of speech sounds
A phonetic transcription is a way of representing sounds in print. The IPA (International Phonetic Alphabet) is a standard among phonetic alphabets, with symbols that correspond bi-uniquely to the sounds of the world’s languages. This means that, unlike spelling symbols, the same phonetic symbol always represents the same sound, and vice versa. In other words, unlike the relationship between speech sounds and spelling, there is a one-to- one correspondence between phonetic symbols and the sounds they represent. This is why trained phoneticians can read a phonetic transcription of any language and sound fluent in it, even if they have no idea how to speak (or spell!) the language.
Figure 4.1 below gives the set of phonetic symbols used in this book. In the token words included in the table, the letters that correspond to the sounds on the left are in bold italic font. When consulting phonetics literature, or dictionaries that include IPA transcriptions, you may notice that certain vowels are transcribed using an additional symbol [ː] following the vowel symbol. This indicates vowel length, and a corresponding distinction between long and short vowels present in some languages and some varieties of English, e.g. bean vs. bin, respectively. Many dictionaries also mark the stressed syllable of words. Intonation in turn has its own set of transcription symbols. For the purposes of this book, you do not need to be familiar with these conventions.
|
Phonetic symbol |
Token word |
|
Phonetic symbol |
Token word |
|
p |
pat |
|
f |
feel |
|
b |
bat |
|
v |
veal |
|
t |
team |
|
s |
seal |
|
d |
deem |
|
z |
zeal |
|
k |
card |
|
i |
bean |
|
ɡ |
guard |
|
æ |
ban |
|
m |
mean |
|
ɑ |
barn |
|
n |
seen |
|
u |
boon |
|
ŋ |
pang |
|
|
|
Figure 4.1. Phonetic symbols used in this book
Phonetic transcriptions are usually given in square brackets. For example, the transcription of the word cat is represented [kæt].
Activity 4.4
Practise transcribing these words, using the phonetic symbols introduced above. Remember to focus on how the words are pronounced, not on how they are spelt.
|
fang |
goof |
moose |
piece |
|
scarf |
snack |
speak |
tax |
4.4 The analysis of speech sounds
According to the phonetics literature, there are two major ways of describing and labelling speech sounds:
- The IPA (International Phonetic Association) approach. Note that the abbreviation IPA stands for two different things – an alphabet and an association.
- The DF (Distinctive Feature) approach.
Both approaches draw on articulatory features of speech such as the ones that we have discussed in this chapter, and both therefore propose a universal framework for the description of human speech sounds. However, each approach takes a different perspective to look at speech sounds. This naturally results in alternative classifications of speech sounds, that do not always overlap across the two frameworks. As we’ve noted before, alternative analyses of this kind are as common in linguistics as in other sciences. They are part and parcel of our quest to understand, and they should be viewed as the probing tools that they are. It’s up to us, as users of these tools, to choose the one that we deem most useful to approach the object of our inquiry, or to come up with a more illuminating alternative.
There are two major differences between the IPA and DF frameworks.
- The IPA approach views vowels and consonants as fundamentally distinct types of sounds. The DF approach views all speech sounds as fundamentally similar.
- The IPA assumes a set of articulatory configurations whose combined presence in the articulation of a sound defines that sound. The DF approach assumes a set of articulatory configurations, each of which can be present [+] or absent [-] in the articulation of a sound, on a binary basis.
We now comment on each of these differences in turn. Because IPA analyses of speech sounds view vowels and consonants as radically different in terms of their articulation, they make a principled distinction between the classification of vowels and consonants. DF analyses don’t.
The IPA uses two distinct sets of articulatory configurations, one to characterise vowels and another to characterise consonants, each with their own set of terms. Consonants are described in terms of three articulatory configurations, namely, vocal cord vibration, place of articulation, and manner of articulation. Any consonant can be uniquely described using these three criteria. For example, [d] is a voiced alveolar plosive; [s] is a voiceless alveolar fricative. Vowels are described in terms of three other articulatory configurations, namely, lip rounding, tongue height, and tongue backness. So the vowel in bean, for example, can be uniquely described as unrounded close front, while that in boon is rounded close back.
In contrast, the DF framework uses the same set of criteria for all speech sounds. Each configuration of the vocal tract corresponds to an articulatory feature that allows us to distinguish one speech sound from another. These features are therefore distinctive. For example, raising the body of the tongue characterises the articulation of sounds like [i] and [k], as opposed to [ɑ] and [z]. A feature that allows us to distinguish between the first and the second set of sounds is therefore relevant for our characterisation of speech, and is called [high] (distinctive feature labels are usually represented in square brackets). Or, vocal cord vibration, labelled [voice], allows us to distinguish [i, α, z] from [k]. Or, the smoothness of the airflow through the vocal tract distinguishes [i, ɑ] from [z, k], and is represented in a feature called [sonorant].
The second difference between IPA and DF analyses concerns the way each of them views the articulatory make-up of a speech sound. For the IPA, a sound consists of a pool of articulations that, together, produce that sound. For example, [d] is voiced, and alveolar, and plosive, and [i] is unrounded, and close, and front. To use an analogy, a girl would likewise be characterised by the pool of properties human, and female, and child. The presence of these features makes a sound (or a girl) unique. In DF approaches, a distinct sound depends on whether specific features of articulation are activated or not in its production. For example, [i] is [+sonorant] and [z] is [-sonorant], [d] is [+voice] and [t] is [-voice]. A girl could be described as [+human -male -adult]. The interplay of features, activated as well as inactivated, is unique to the sound.
Given the introductory nature of this book, we will not go into theoretical detail relating to the two frameworks. However, you will come across published material on phonetic analysis that often makes free use of terminology from either approach, and often in the same research piece. The set of tables that we propose below will, we hope, facilitate your learning about phonetics.
We start with the IPA, because this was the first analytical framework available to phoneticians. The IPA was founded in 1886, and the first DF proposals appeared in the early 1950s. Throughout the discussion in the remainder of this chapter, you should keep in mind that the use of the International Phonetic Alphabet in transcriptions does not imply subscription to the classificatory approach of the International Phonetic Association. DF analyses may use IPA phonetic symbols. A set of printable symbols and a theoretical stance about the classification of the sounds that these symbols represent are two different things.
IPA representations of speech sounds
Below are two samples of IPA charts, one for consonants and one for vowels.
|
|
Place of articulation |
|||
|
(bi)labial |
alveolar |
velar |
||
|
Manner of articulation |
plosive |
p b |
t d |
k ɡ |
|
nasal |
m |
n |
ŋ |
|
|
fricative |
f v |
s z |
|
|
Figure 4.2. Partial IPA consonant chart
By IPA convention, in paired voiced vs. voiceless sounds, the voiceless sound appears to the left of its voiced counterpart. Note that the blank box in the chart simply indicates that we do not deal with velar fricative articulations in this book. Many languages and language varieties have velar fricatives, like German, e.g. at the end of the word Bach, or Scottish English, e.g. at the end of the word loch (a word for ‘lake’, as in Loch Ness).
Different IPA labels referring to place of articulation can be combined to provide more detailed articulatory descriptions. For example, the sounds [f, v] are usually described as labio-dental fricatives, accounting for the fact that their pronunciation involves both the lips and the teeth.
Vowel space is usually plotted inside a diagram like the one in Figure 4.3, called a vowel quadrilateral.
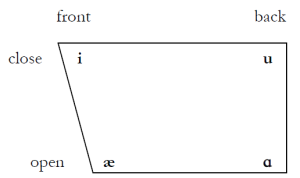
The diagram represents the left profile of the inside of the mouth, the side that is also represented in standard diagrams of the vocal tract. Each of the four sides in the diagram represents the top, bottom, front and back of the oral cavity. The four vowels discussed in this chapter can be plotted at the four angles of the quadrilateral. The vowel quadrilateral accounts for tongue movement only. It does not represent lip movement.
DF representations of speech sounds
Here is a summary of a sample of distinctive features.
|
|
|
Yes |
No |
|
Manner of articulation |
the airflow is smooth |
[+sonorant] |
[-sonorant] |
|
there is contact of articulators |
[+stop] |
[-stop] |
|
|
the air flows through the nasal cavities |
[+nasal] |
[-nasal] |
|
|
|
|
Yes |
No |
|
Place of articulation |
the body of the tongue is raised |
[+high] |
[-high] |
|
the body of the tongue is lowered |
[+low] |
[-low] |
|
|
the body of the tongue is fronted |
[+front] |
[-front] |
|
|
the body of the tongue is retracted |
[+back] |
[-back] |
|
|
one or both lips are involved |
[+labial] |
[-labial] |
|
|
the teeth are involved |
[+dental] |
[-dental] |
|
|
the tongue blade/tip is involved |
[+coronal] |
[-coronal] |
|
|
Voicing |
the vocal cords vibrate |
[+voice] |
[-voice] |
Figure 4.4. Sample DF labels
DF approaches typically use a matrix-like table to classify speech sounds, where vowels and consonants are plotted together.
The matrix in Figure 4.5 gives a classification of the speech sounds that are represented by the phonetic symbols in its first column. For example, the four vowel symbols [i, æ, !, u] represent oral vowels, and the feature [nasal] is accordingly marked for these vowels with a minus symbol. Many languages have nasalised vowels (e.g. French, Portuguese, Hokkien), for which there are different phonetic symbols from the ones given here, and whose [nasal] feature is therefore marked with a plus sign in a DF matrix. We marked the consonants [t, d, n] as [-dental] in the matrix, although they can be [+dental] in several languages and in several varieties of English. When you articulate [t, d, n] as [+dental], the tip of your tongue touches your upper teeth instead of the alveolar ridge. In all cases, [t, d, n] are [+coronal].
In the matrix below, we use the following conventions:
son: sonorant lab: labial dent: dental cor: coronal
|
|
Manner of articulation |
Place of articulation |
Voicing |
||||||||
|
son |
stop |
nasal |
high |
low |
front |
back |
lab |
dent |
cor |
voice |
|
|
p |
– |
+ |
– |
– |
– |
– |
– |
+ |
– |
– |
– |
|
b |
– |
+ |
– |
– |
– |
– |
– |
+ |
– |
– |
+ |
|
t |
– |
+ |
– |
– |
– |
– |
– |
– |
– |
+ |
– |
|
d |
– |
+ |
– |
– |
– |
– |
– |
– |
– |
+ |
+ |
|
k |
– |
+ |
– |
+ |
– |
– |
+ |
– |
– |
– |
– |
|
ɡ |
– |
+ |
– |
+ |
– |
– |
+ |
– |
– |
– |
+ |
|
m |
+ |
+ |
+ |
– |
– |
– |
– |
+ |
– |
– |
+ |
|
n |
+ |
+ |
+ |
– |
– |
– |
– |
– |
– |
+ |
+ |
|
ŋ |
+ |
+ |
+ |
+ |
– |
– |
+ |
– |
– |
– |
+ |
|
f |
– |
– |
– |
– |
– |
– |
– |
+ |
+ |
– |
– |
|
v |
– |
– |
– |
– |
– |
– |
– |
+ |
+ |
– |
+ |
|
s |
– |
– |
– |
– |
– |
– |
– |
– |
– |
+ |
– |
|
z |
– |
– |
– |
– |
– |
– |
– |
– |
– |
+ |
+ |
|
i |
+ |
– |
– |
+ |
– |
+ |
– |
– |
– |
– |
+ |
|
æ |
+ |
– |
– |
– |
+ |
+ |
– |
– |
– |
– |
+ |
|
ɑ |
+ |
– |
– |
– |
+ |
– |
+ |
– |
– |
– |
+ |
|
u |
+ |
– |
– |
+ |
– |
– |
+ |
+ |
– |
– |
+ |
Figure 4.5. Sample DF matrix
It’s worth highlighting that in both frameworks, IPA and DF, the different configurations of the articulators are independent of one another. For example, within the IPA framework, a plosive can be voiced or voiceless, labial, alveolar or velar. Similarly, within the DF framework, a [+high] sound can be [+front] or [+back], [+labial] or [-labial]. The important thing to keep in mind is that each movement of each articulator produces one particular effect on the flow of air. It is the combination of concerted effects that produces a speech sound.
Activity 4.5
Redundancy in phonetic descriptions
Our realisation that a sound is the result of a complex interplay of factors does not mean that its description must reflect this complexity. If description consistently matched real-world complexity, nobody would be able to learn about Newton’s Laws of Motion in secondary school. Science of course strives to make sense of complex phenomena by means of simple descriptive statements. Let’s illustrate this point with an example. From the DF matrix in Figure 4.5, we may conclude that the English sound represented by the symbol [n] can be described as:
(4.2) [+son +stop +nasal -high -low -front -back -lab -dent +cor +voice]
This description is accurate because it accounts for the uniqueness of [n] among all other sounds. But it is also, to say the least, cumbersome. It is like describing a cat, as opposed to a human being, as having fur, two eyes, four limbs, mammal features, claws, a stomach, whiskers, feline features and small size. Some of these properties can be inferred from other properties. For example, “four limbs” can be predicted from “mammal features”. Other properties apply equally well to other members of a larger class. For example, both cats and humans have two eyes and a stomach. Likewise, in terms of distinctive features, [+nasal] implies [+sonorant], because nasal airflow is smooth (unless you’re blowing your nose!). Also, most sounds in Figure 5.5 share features like [-low -front]. An equally adequate description of the sound [n], in terms of distinctive features that apply to English is:
(4.3) [+nasal +cor]
This is so because, in English, there are only three nasal sounds, [m, n, η]. Specifying their place of articulation is thus enough to describe the uniqueness of each nasal in this language. The description in (4.3) is as informative as the one in (4.2), and it is clearly simpler. We should stress, however, that (4.3) provides a description of [n] that applies to a single language, in this case English. In other languages, the set of nasal sounds may include vowels, as we noted above, or other consonants besides [+stop], or [+stop] nasals that are [+coronal] and [+dental]. The analysis of sounds in different languages must of course take into account the specific articulatory patterns that are found in each language.
Our discussion of the description in (4.2) highlights two important points. The first is that a DF analysis provides us with more labels than are necessary for the description of single sounds in particular languages. This is also true of the IPA approach. We saw that the combination of velar and fricative articulations does not exist in English, although velar and fricative are useful labels to describe other articulatory combinations in this language. In other words, both IPA and DF frameworks contain some degree of redundancy, in that they specify more structure than is required for the actual description of any given speech sound. A complete IPA and DF chart of the full set of articulations involved in English, for example, would show greater redundancy still. We will see another example of redundant analysis in section 6.3.1, where a theoretical “slot” was posited for inflectional prefixes, a unit that is not needed for the analysis of English morphemes, but which occurs in other languages. Redundancy is a feature of any scientific analysis, and of taxonomies in particular. For example in zoology, mammal and eight legs are constructs that usefully describe different types of living organisms, although there are no eight-legged mammals. Redundancy is also a feature of language itself, in fact an invaluable one in everyday communication.
The second point that we wish to note is that redundancy operates at two different levels, the level of individual languages and the level of language in general. We saw above that (4.3) removes the redundancies found in (4.2) for the description of one sound in one language. We said that one of the reasons why we were able to simplify (4.2) is that some features are predictable from other features. In English, [+nasal] predicts [+stop], because all English nasals involve a complete closure in the mouth, blocking the airflow. But we also said that [+nasal] implies [+sonorant], because nasal airflow is smooth, and this is a universal entailment. It applies to nasal sounds in any language. An articulation like *[+nasal -sonorant] is therefore not generally found: we already know that not all theoretically possible articulations occur in practice. This is often due to simple physical reasons, that apply to any human being and therefore to any language. For example, try producing a speech sound which involves contact between your soft palate and your lower lip!
Activity 4.6
- Which of the following (sets of) features necessarily implies the other? Circle your answers. The symbol ⇒ stands for ‘implies’.
|
(a) [+high] ⇒ [-low] (d) [+voice] ⇒[+son] |
(b) [-low] ⇒[+high] (e) [+son +stop] ⇒[+nasal] |
(c) [+stop] ⇒[-son] (f) [+cor] ⇒[-dent] |
2. Which of the following combinations are impossible to articulate? Circle your answers.
|
(a) [+dental +coronal] |
(b) [+front +back] |
(c) [-front -back] |
|
|
(d) [+sonorant +stop] |
(e) [+nasal -stop] |
(f) [+cor +lab] |
|
Activity 4.7
The clear differences, that we have highlighted, between IPA and DF analyses should not obscure the fact that their object is the same: the articulation of human speech sounds. For example, the same sound [p] can be identified as a voiceless bilabial plosive or as [-son +stop -voice +lab]. These descriptions do not reflect a difference in the articulation of the sound [p]. They reflect a preference for a set of labels and representations that each framework, or theory, finds more useful for the purposes of their investigation.
Despite the different assumptions and insights into articulation that each of the two framework offers, the phonetics literature does not always show a clear-cut choice between one or the other. As we noted at the beginning of this section, phoneticians may draw on terminology from either account, when describing their research. This is often so for the sake of simplicity. For example, it is quicker (and neater) to say plosive than to say [-son +stop]. But it is also simpler to say [+sonorant] than to say vowels and nasals. This terminological hesitation reflects the fact that in phonetics, as in any science, the search continues, for the most economical way of making sense of our observations.
Activity 4.8
4.5 Intonation and tone
Vowels are voiced sounds, produced with a smooth airflow. These two features make vowels the sounds upon which intonation is chiefly modulated.
Intonational modulation, or speech melody, is one crucial carrier of linguistic meaning in any language.
Try the following
Imagine yourself in two different situations where you might use the following utterance, one jokingly, one deeply annoyed:
Oh, shut up!
If you try to pronounce this utterance to match the suggested feelings, you’ll find that you pronounce the “same” utterance in two very different ways. In fact, you’ll be pronouncing two different utterances, with two distinct meanings.
Intonation can be said to result from rapid changes in the tension and rate of vibration of the vocal cords. The vocal cords are folds of elastic tissue that can stretch or contract, and vibrate at a higher or lower rate, much like violin strings. Associated with these changes, the length of the vocal tract may be modified during speech, due to the vertical mobility of the larynx.
Try the following
Touch your larynx gently with your fingers, or look in a mirror with your chin lifted up, so you can see your larynx clearly. Now sing the highest note you can sing, and then the lowest, and then go from one to the other, a few times in a row. You’ll feel/see your larynx moving up for the high note, and down for the low one, assisting the higher and lower rate of vibration of the vocal folds, respectively. The effect that these combined actions have on the column of air inside your vocal tract gives a similar impression to the one achieved by a “bottle concert”, where you fill similar bottles with different amounts of liquid and then either blow into them or strike them with some hard instrument. You’ll get a higher note when there’s a higher rate of vibration inside the bottle and inside your vocal tract, and lower notes for lower rates.
Like any other linguistic system, intonation systems vary both across and within languages. However, two basic distinctions in the form of intonation patterns appear to be consistently associated with two sets of meanings, according to whether our tone of voice falls or rises.
Falling tones
Falling tones, or falls, result from a decrease in the rate of vibration of the vocal cords. Falls are typically associated with statements and commands. These types of utterances require minimal or no verbal response from the listener, and falling tones are therefore said to convey a closed set of meanings, in that they close off communication.
Rising tones
Rising tones, or rises, result from an increase in the rate of vibration of the vocal cords. Rises typically signal questions, which call for some response from the listener, and continuation, when the speaker goes on speaking. That is, the use of rising tones in an utterance indicates that the utterance is not complete, and rises are therefore associated with an open set of meanings.
Activity 4.9
If you have difficulty producing (and hearing) falling vs. rising tones, or level tones, try Collins and Mees’ (2003: 118) analogy: “The engine of a motor car when ‘revving up’ to start produces a series of rising pitches. When the car is cruising on the open road, the engine pitch is more or less level. On coming to a halt, the engine stops with a rapid fall in pitch.”
Intonational modulation operates across whole utterances, including those that may comprise a single word. In many languages, the difference between a statement and a question is signalled by intonation alone, a fall vs. a rise at the end of the utterance, respectively, without the associated change in word order that is common in standard uses of English.
All languages make intonational distinctions of this kind, but there are other uses of pitch in language. Pitch modulation may operate on single words, distinguishing between different lexical meanings of the same string of vowels and consonants. This is the domain of tone. Here is one example from Ngbaka, spoken in the Central African Republic. This language has level tones, meaning that the tone is kept even, neither rising nor falling, throughout the pronunciation of the words:
Ngbaka
| Word
[ma] |
Tone
low, level |
Meaning
‘magic’ |
|
[ma] |
mid, level |
‘I’ |
|
[ma] |
high, level |
‘to me’ |
Figure 4.6. Examples of tones in Ngbaka
Asian languages like Mandarin, African languages like Hausa, and several American Indian languages are tone languages, distinct from intonation languages like English or Malay. Other languages, like Swedish and Japanese, combine features of intonation and tone languages.
As a concluding thought, it is interesting to note that despite the crucial role played by pitch modulation across all languages, the meanings conveyed by such modulation are hardly represented in spelling. Question marks vs. exclamation marks, for example, give an even rougher approximation to the various rises and falls of real-life language than the English spellings bus, cress , science , city, mouse , flaccid, give to the sound [s]. The deficient representation of intonation in print highlights the very limited resources of written forms of language to convey the full range of linguistic meanings. It is often the case that the meaning that you intend for an utterance is in fact given by intonation, rather than by the words that you use. We’ve all heard the saying: it’s not what you say but how you say it that counts. Or, as the American linguist Kenneth Pike (1945: 22) strikingly put it, “[…] if a man’s tone of voice belies his words, we immediately assume that the intonation more faithfully reflects his true linguistic intentions.”
Activity 4.10
Activity 4.11
In this chapter, we have provided a very brief overview of the range and variety of speech sounds that can be produced by the human vocal tract. Obviously, no language makes use of all possible speech sounds. In the next chapter, we look at how speech sounds are organised and used in languages.
Food for thought
When it’s English that we SPEAK
Why is STEAK not rhymed with WEAK? And couldn’t you please tell me HOW COW and NOW can rhyme with BOUGH?
I simply can’t imagine WHY HIGH and EYE sound like BUY.
We have FOOD and BLOOD and WOOD, And yet we rhyme SHOULD and GOOD.
BEAD is different from HEAD,
But we say RED, BREAD, and SAID. GONE will never rhyme with ONE
Nor HOME and DOME with SOME and COME.
NOSE and LOSE look much alike,
So why not FIGHT, and HEIGHT, and BITE?
DOVE and DOVE look quite the same,
But not at all like RAIN, REIN, and REIGN.
SHOE just doesn’t sound like TOE, And all for reasons I don’t KNOW. For all these words just prove to ME That sounds and letters DISAGREE.
Further reading
Collins, Beverley and Mees, Inger M. (2003). How we produce speech. In practical phonetics and phonology: A resource book for students. London/New York: Routledge, pp. 25-39.
(This book includes a CD with sound files to listen to and practise with.) Deterding, David H. and Poedjosoedarmo, Gloria R. (1998). Chapter 2.
Speech production. In The sounds of English. Phonetics and phonology for
English teachers in Southeast Asia. Singapore: Prentice Hall, pp. 9-13.
Roach, Peter (1993). Chapter 2. The production of speech sounds. In English phonetics and phonology. A practical course. Cambridge: Cambridge University Press, pp. 8-17.
References
Collins, Beverley and Mees, Inger M. (2003). How we produce speech. In practical phonetics and phonology: A resource book for students. London/New York: Routledge.
Pike, Kenneth L. (1945). The intonation of American English. Ann Arbor: University of Michigan Press.
Attribution
This chapter has been modified and adapted from The Language of Language. A Linguistics Course for Starters under a CC BY 4.0 license. All modifications are those of Régine Pellicer and are not reflective of the original authors.
